MLP의 파라미터 개수가 많이지면서 각각의 weigh와 bias를 학습시키는 것이 매우 어려워진다.
Solution
‘Backpropagation (오차역전파법)’을 사용하여 가중치 매개변수의 기울기를 효율적으로 계산한다.
Training Process (Learning) : Identify w value that minimizes the Loss
Gradient Descent Algorithm: If we are using thousands of weigh, it is impossible to identify w value. Gradient Descent Algorithm is a systemic way that automatically computes w value. (α is usually small value like 0.01) Back-Propagation : In the case of complicated (non-linearity) network, back-propagation is better way for compute the gradient of loss with respect to w using chain rule on the computational graph.
1. Computational Graph (계산 그래프)
계산 과정을 그래프로 나타낸 것이다.
node와 edge (node 사이의 직선)로 표현한다.
국소적 (자신과 직접 관계된 작은 범위) 계산을 전파함으로써 최종 결과를 얻는다.
Computational Graph의 장점
전체가 아무리 복잡해도 각 노드에서는 단순한 계산에 집중하여 문제를 단순화할 수 있다.
계산 그래프는 중간 계산 결과를 모두 보관할 수 있다.
역전파를 통해 미분을 효율적으로 계산할 수 있다.
Forward Propagation (순전파) : 계산을 왼쪽(출발점)에서 오른쪽(종착점)으로 진행하는 단계
Backward Propagation (역전파) : 계산을 오른쪽(종착점)에서 왼쪽(출발점)으로 진행하는 단계, 국소적 미분을 전달
2. Chain Rule (연쇄법칙)
국소적 미분을 전달하는 원리 = 계산 그래프 상의 역전파
‘합성 함수의 미분은 합성 함수를 구성하는 각 함수의 미분의 곱으로 나타낼 수 있음'
3. 역전파의 계산 절차
신호E에 노드의 국소적 미분(f’(x), 즉 x에 대한 y의 미분)을 곱한 후 다음 노드로 전달한다.
덧셈 노드의 역전파 : 상류에서 전해진 미분에 1을 곱하여 하류로 흘린다. 즉, 1을 곱하기만 할 뿐의므로 입력된 값을 그대로 다음 노드로 보내게 된다.
곱셈 노드의 역전파 : 상류의 값에 순전파 때의 입력 신호들을 서로 바꾼 값을 곱해서 하류로 보낸다. 덧셈의 역전파에서는 상류의 값을 그대로 흘려 보내서 순방향 입력 신호의 값은 필요하지 않지만, 곱셈의 역전파는 순방향 입력 신호의 값이 필요하다. 그래서 곱셈 노드를 구현할 때는 순전파의 입력 신호를 변수에 저장해둔다.
4. 계층 구현 (계층 : 신경망의 기능 단위)
Activation Function (활성화 함수)
신경망모델의 각 layer에서는 input 값과 W, b를 곱, 합 연산을 통해 a = WX + b를 계산하고 마지막에 활성화 함수를 거쳐 h(a)를 출력한다.
각 layer마다 sigmoid, softmax, relu 등 …. 여러 활성화 함수를 이용한다.
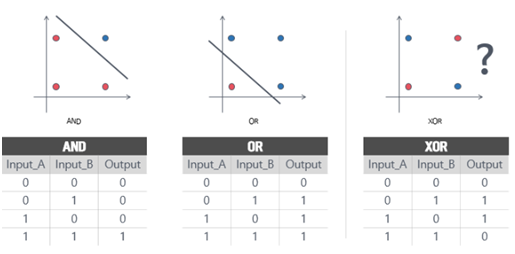
Q : Activation 함수를 쓰는 이유는? A : 선형 분류기는 XOR과 같은 non-linear한 문제를 해결할 수 없다. 이를 해결 하기 위해 hidden layer이란 개념을 도입하였지만, hidden layer을 무작정 쌓기만 한다고 해서 퍼셉트론을 선형 분류기에서 비선형 분류기로 바꿀 수 없다. 왜냐하면 linear한 연산을 갖는 layer을 수십 개 쌓아도 결국 이는 하나의 linear한 연산이기에 non-linearity를 해결 할 수 없다. 활성화 함수를 사용하면 입력 값에 대한 출력 값이 linear하게 나오지 않으므로 선형분류기를 비선형 시스템으로 만들 수 있다. -> 따라서 MLP (Multiple Layer Perceptron)은 단지 linear layer을 여러 개 쌓는 개념이 아닌 활성화 함수를 이용한 non-linear 시스템을 여러 layer로 쌓는 개념
ReLU 계층
ReLU 함수
순전파 때의 입력인 x가 0보다 크면 역전파는 상류의 값을 그대로 하류로 흘려 내린다. 반면, 순전파 때 x가 0 이하면 역전파 때는 하류로 신호를 보내지 않는다 (0을 보낸다)
ReLu 계층의 계산 그래프
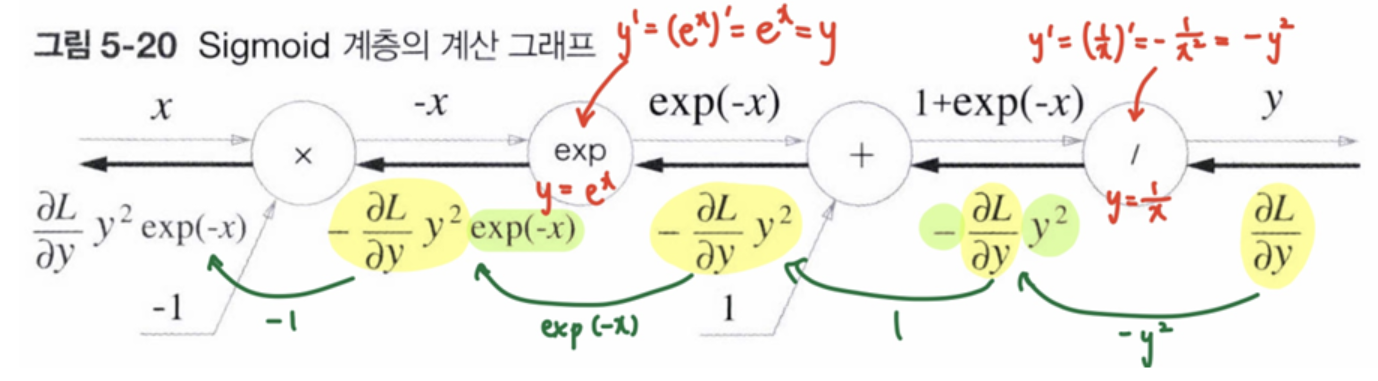
Sigmoid 계층
Sigmoid 함수
Sigmoid 계층의 계산 그래프
Sigmoid 계층의 계산 그래프 (간소화)
Sigmoid 계층의 역전파는 순전파의 출력 (y)만으로 계산할 수 있다.
Affine 계층
신경망의 순전파에서는 가중치 신호의 총합을 계산하기 때문에 행렬의 곱을 사용한다.
뉴런의 가중치 합 : Y = np.dot(X, W) + B (X : 입력값, W : 가중치 매개변수, B : 편향)
행렬의 곱은 기하학에서 Affine Transformation이라 한다.
Affine Transformation을 수행하는 처리를 Affine 계층이 구현한다.
행렬의 곱에서는 대응하는 차원의 원소 수를 일치 시켜야 한다.
C의 형상은 행렬A의 행 수와 행렬B의 열 수가 됨
1차원 배열 일 때도 대응하는 차원의 원소 수를 일치 시켜야함
Numpy 배열
Affine 계층의 역전파 Q : 행렬이 전치되는 이유가 행렬을 미분한 결과인가? (http://taewan.kim/post/backpropagation_matrix_transpose/) A : 행렬을 미분하는 과정에서 행렬이 전치되는 것이 아니라, 각 W의 요소를 미분하고 그 결과 수식을 선형대수의 행렬로 단순화하는 과정에서 행렬의 shape이 결정된다. 미분 과정에서 행렬이 전치되는 것이 아니라, 각 요소의 연산을 선형대수화하는 과정에서 행렬의 shape이 결정되고 전치되는 것이다.
Affine 계층의 계산 그래프 (노드 사이에 '스칼라 값'이 아닌 '행렬'이 흐름)
배치용 Affine 계층
입력 데이터로 X 하나만을 고려하지 않고, 데이터 N개를 묶어 순전파를 하는 경우
배치 : 묶은 데이터
배치용 Affine 계층의 계산 그래프
Softmax-with-Loss 계층
Softmax 함수 : 입력 받은 값을 출력으로 0~1사이의 값으로 모두 정규화하며 출력 값들의 총합은 항상 1이 되는 특성을 가진 함수























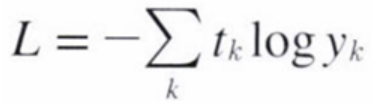

댓글